Every AEM developer faced with below exception which means that we are exceeded the limit of nodes for reading:
java.lang.UnsupportedOperationException: The query read or traversed more than 100000 nodes. To avoid affecting other tasks, processing was stopped. at org.apache.jackrabbit.oak.query.FilterIterators.checkReadLimit(FilterIterators.java:70) at org.apache.jackrabbit.oak.plugins.index.Cursors.checkReadLimit(Cursors.java:67) at org.apache.jackrabbit.oak.plugins.index.lucene.LucenePropertyIndex$LucenePathCursor$1.next(LucenePropertyIndex.java:1730) at org.apache.jackrabbit.oak.plugins.index.lucene.LucenePropertyIndex$LucenePathCursor$1.next(LucenePropertyIndex.java:1711) at com.google.common.collect.Iterators$7.computeNext(Iterators.java:646) at com.google.common.collect.AbstractIterator.tryToComputeNext(AbstractIterator.java:143) at com.google.common.collect.AbstractIterator.hasNext(AbstractIterator.java:138) at org.apache.jackrabbit.oak.plugins.index.Cursors$PathCursor.hasNext(Cursors.java:216) at org.apache.jackrabbit.oak.plugins.index.lucene.LucenePropertyIndex$LucenePathCursor.hasNext(LucenePropertyIndex.java:1751) at org.apache.jackrabbit.oak.query.ast.SelectorImpl.next(SelectorImpl.java:432) at org.apache.jackrabbit.oak.query.QueryImpl$RowIterator.fetchNext(QueryImpl.java:824) at org.apache.jackrabbit.oak.query.QueryImpl$RowIterator.hasNext(QueryImpl.java:851) at org.apache.jackrabbit.oak.jcr.query.QueryResultImpl$1.fetch(QueryResultImpl.java:98)
In this situation, we can:
- define the oak index for a query
- try to redesign taxonomy of a repository or structure if it might be improved
- update oak indexes to cover the query
- use oak:Unstructured instead of nt:unstructured and sling:Folder instead of sling:OrderedFolder in a case where an order is not required
- etc.
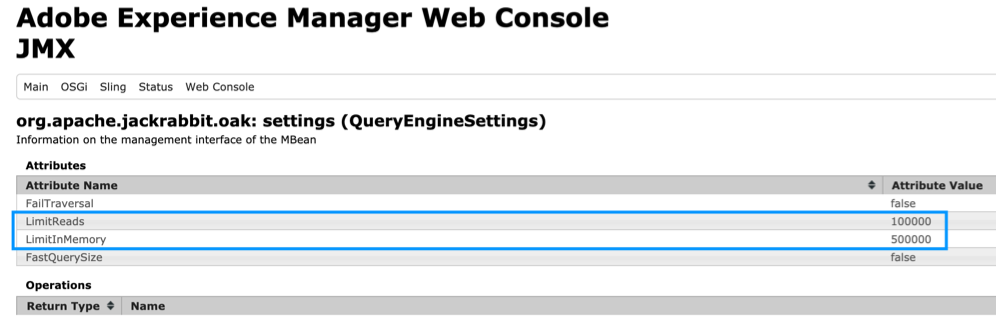
During the development, if we want to skip this error for a while we can increase LimitReads and LimitInMemory parameters for OAK Query Engine:
- navigate to QueryEngineSettings
- increase selected parameters:
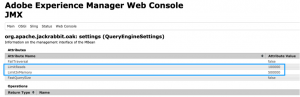
- this is for development stage only, please, do not push this on production
Links to resources for help: